Hay un examen que ningún modelo de inteligencia artificial ha logrado aprobar
Los mejores modelos frontier alcanzan 45% en Humanity's Last Exam; los expertos humanos superan 90%. La brecha es llamativa, pero el hallazgo más incómodo es otro: las máquinas entregan respuestas incorrectas con alta confianza declarada.

No por falta de entrenamiento, ni por falta de datos, ni por falta de presupuesto. Sino porque fue diseñado, precisamente, para que eso no ocurra fácilmente.
1. El examen que los modelos no pueden pasar
A principios de 2025, un consorcio integrado por el Center for AI Safety y Scale AI, junto a cerca de mil expertos afiliados a más de quinientas instituciones en cincuenta países, lanzó el Humanity’s Last Exam (HLE), un conjunto de 2.500 preguntas en más de cien disciplinas —desde matemáticas avanzadas hasta filología clásica, pasando por biología molecular y teoría del derecho— con una condición particular: ninguna respuesta correcta puede recuperarse mediante una búsqueda en internet. El preprint apareció en arXiv en enero de 2025 y la versión revisada por pares fue publicada en Nature en enero de 2026 [1][2]. Se trata, en principio, del conocimiento que solo alguien que ha pasado años dentro de una disciplina puede producir de forma confiable. Al corte de esta edición, los mejores modelos disponibles alcanzan entre el 37% y el 45% de precisión, según la configuración y el marcador consultado [3][4]. Los expertos humanos que respondieron preguntas de su propio dominio superan, en promedio, el 90% [1].
Antes del HLE existía el MMLU —Massive Multitask Language Understanding—, un benchmark que durante años funcionó como referencia para medir capacidad de los modelos de lenguaje. El problema es que dejó de funcionar: los sistemas actuales lo superan con más del 90% de precisión, lo que lo convierte en un instrumento demasiado fácil para discriminar entre modelos realmente distintos. El HLE y el ARC-AGI nacen, entre otras razones, como respuesta a ese agotamiento.
El ARC-AGI —desarrollado por François Chollet y el equipo de ARC Prize a partir del paper On the Measure of Intelligence (2019) [5]— opera bajo una lógica diferente pero complementaria: sus tareas son fáciles para cualquier niño de seis años, pero extraordinariamente difíciles para los modelos actuales. Patrones visuales simples, razonamiento de sentido común, analogías elementales. La idea es medir razonamiento fluido —aquello que no puede memorizarse— en lugar de conocimiento acumulado. Su segunda generación, ARC-AGI-2, fue lanzada el 24 de marzo de 2025 con el objetivo declarado de ser aún más difícil para sistemas de IA manteniendo la misma facilidad para humanos [6][7]. Son dos filosofías distintas de lo mismo: construir un espejo que no mienta.
2. Anatomía de un benchmark: cómo se fabrica una prueba para máquinas
Diseñar un benchmark útil es, en sí mismo, un problema no trivial. El HLE fue construido con preguntas que cumplen tres condiciones: son verificables (tienen una respuesta correcta objetiva), no están indexadas en la web de forma accesible, y fueron elaboradas por especialistas con grado de máster, doctorado o equivalente en sus áreas. El proceso de selección incluyó un filtro automático previo —cada pregunta candidata se probaba primero contra varios modelos frontier, y aquellas que los modelos lograban resolver eran rechazadas— seguido de múltiples rondas de revisión experta. Entre febrero y marzo de 2025, un programa público de bug bounty permitió a la comunidad reportar problemas, y las preguntas detectadas como searchable —recuperables vía web— fueron eliminadas y sustituidas. En octubre de 2025, el proyecto lanzó HLE-Rolling, una versión dinámica con actualización continua [1][2].
El ARC-AGI-2, por su parte, opera con matrices de patrones que requieren identificar reglas implícitas y aplicarlas a casos nuevos. Su diseño incorpora cambios deliberados respecto de la versión original: los eval sets crecieron de 100 a 120 tareas, se eliminaron explícitamente todas las tareas resueltas por fuerza bruta en el concurso Kaggle de 2020, y se ejecutaron estudios controlados con más de 400 participantes humanos para garantizar que cada tarea fuera resoluble pass@2 por al menos dos humanos, las mismas reglas que se aplican a los sistemas de IA [6][7]. Su fortaleza es que ningún modelo puede resolverlo simplemente por haber visto suficientes ejemplos similares: la lógica de cada tarea es, en principio, única. Su limitación reconocida es que las tareas son bidimensionales y visuales, lo que no captura la complejidad del razonamiento en lenguaje natural ni en dominios no perceptivos.
Ambos instrumentos tienen límites. Ningún benchmark mide motivación, creatividad genuina, capacidad de investigación autónoma ni habilidad para formular buenas preguntas. Miden ejecución en condiciones controladas, que es útil pero no suficiente para inferir inteligencia en sentido amplio.
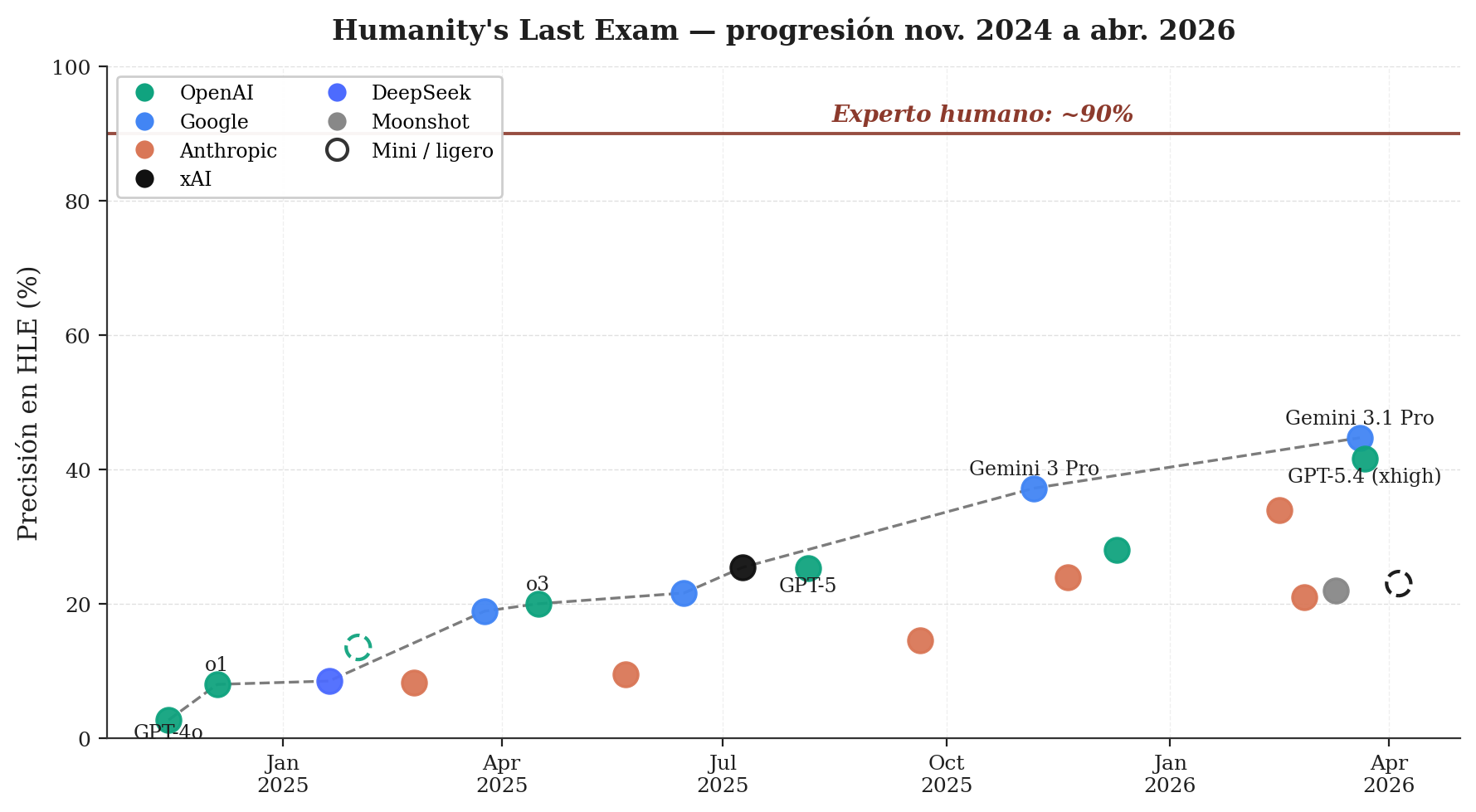
3. Los números sobre la mesa: qué dice el marcador hoy
Al 22 de abril de 2026, el leaderboard público de HLE mantenido por Artificial Analysis registra los siguientes resultados en configuración sin herramientas: Gemini 3.1 Pro Preview lidera con 44,7% de precisión en inferencia estándar, seguido por GPT-5.4 en configuración de alta computación con 41,6%, GPT-5.3 Codex también en alta computación con 39,9%, y Gemini 3 Pro Preview con 37,2% [3]. Un marcador independiente mantenido por LMCouncil, con un juez distinto y por tanto cifras algo menores, registra snapshots similares en la misma ventana temporal [4]. El baseline humano experto reportado en el paper HLE se mantiene en torno al 90% [1]. La brecha, medida al día de hoy, es de más de cuarenta puntos porcentuales entre el mejor modelo y el especialista humano en su propio campo.
El panorama de ARC-AGI-2 es más interesante porque obliga a distinguir dos regímenes de medición. En la competición oficial ARC Prize 2025, que se desarrolló en Kaggle entre marzo y noviembre de 2025 bajo restricciones estrictas de cómputo —aproximadamente cincuenta dólares de presupuesto por envío para resolver 120 tareas—, el Gran Premio de setecientos mil dólares reservado para la primera solución que superara el 85% quedó sin adjudicar. El anuncio oficial de ARC Prize confirma que ningún equipo alcanzó el umbral bajo esas restricciones, y que solo se adjudicaron premios menores de Score y Paper [7][8]. Fuera de esas restricciones, en evaluaciones externas con cómputo no declarado, los números son muy distintos: al 21 de abril de 2026, BenchLM.ai reporta a GPT-5.4 Pro liderando ARC-AGI-2 con 83,3%, seguido por Gemini 3.1 Pro con 77,1% y Grok 4.20 con 53,3% [9]. El baseline humano, medido por el propio ARC Prize, es de 100% para el panel de dos o más participantes y 60% para el humano promedio individual [6].
La distancia entre ambos números —el Gran Premio no adjudicado bajo restricciones y el 83,3% en evaluación abierta— es, en sí misma, el dato más interesante del ejercicio. Lo que los modelos pueden hacer cuando el cómputo es ilimitado no coincide con lo que pueden hacer cuando el cómputo es medido. Y el marketing de la industria tiende a reportar lo primero omitiendo lo segundo.
Lo que estos números dicen, con la precisión que permiten, es que los modelos actuales son herramientas extraordinariamente capaces en tareas bien delimitadas —redacción, síntesis, código, traducción— y que, al mismo tiempo, su capacidad de razonamiento en dominios que exigen novedad y profundidad experta está por debajo de lo que el marketing de la industria sugiere con frecuencia.
4. El precio del pensamiento: tokens, capas y la economía del razonamiento
Un token es, aproximadamente, tres cuartos de una palabra en español. Es la unidad básica con la que los modelos de lenguaje leen y producen texto. Cada token procesado tiene un costo computacional, y ese costo se refleja en el precio que pagan quienes acceden a estos modelos por medio de interfaces de programación.
Los principales actores del mercado —OpenAI, Anthropic, Google DeepMind, entre otros— organizan su oferta en jerarquías explícitas: modelos ligeros, rápidos y baratos para tareas cotidianas; modelos de razonamiento extendido, más lentos y significativamente más caros, para tareas complejas. Tomando la tabla de precios oficial de OpenAI al primer trimestre de 2026 como ejemplo verificable, el escalón va desde gpt-5.4-nano —a 0,20 dólares por millón de tokens de entrada y 1,25 dólares por millón de tokens de salida— hasta gpt-5.4-pro en contexto largo —a 60 dólares por millón de tokens de entrada y 270 dólares por millón de tokens de salida [10]. El modelo más barato y el más caro del mismo proveedor están separados por un factor de entre 216 y 300 veces, no por el orden de uno a veinte que sugieren las comparaciones superficiales. La brecha no es incidental: es la consecuencia directa de que los modelos con razonamiento extendido consumen más cómputo por inferencia —más capas activas, más pasos internos, más verificación cruzada— y cada uno de esos pasos tiene un costo energético y financiero que se traduce en el precio final.
El patrón no es privativo de OpenAI. Anthropic mantiene una jerarquía análoga en su catálogo de abril de 2026: Opus 4.7 —su modelo más capaz— factura a 5 dólares por millón de tokens de entrada y 25 dólares por millón de tokens de salida, mientras que Haiku 4.5 lo hace a 1 y 5 dólares respectivamente. Una brecha de cinco veces entre tope y piso, menor que la de OpenAI pero estructuralmente del mismo tipo [12]. Google, en el caso de Gemini 3.1 Pro Preview, añade una diferenciación adicional por longitud de contexto: los prompts de menos de 200 mil tokens se facturan a 12 dólares por millón de tokens de salida; los de más de 200 mil, a 18 [13]. Pero hay un detalle del tarifario de Google que vale la pena leer con atención: ese precio de salida incluye, de manera explícita, los thinking tokens —los que el modelo produce durante su propio razonamiento interno antes de entregar la respuesta. La industria ya no solo cobra por el texto que el modelo produce para el usuario; cobra, como ítem separado, por el texto que el modelo se produce a sí mismo para pensar. El precio del pensamiento, en este caso, no es una metáfora: es un ítem de lista de precios.
La economía del razonamiento también se hace visible en otra parte inesperada: el costo por tarea reportado por ARC Prize para su propio benchmark. Un panel de humanos resuelve cada tarea de ARC-AGI-2 por aproximadamente 17 dólares. Una solución basada en o3-preview con razonamiento pesado y búsqueda cuesta, según estimaciones oficiales de ARC Prize, alrededor de 200 dólares por tarea —un orden de magnitud superior al humano— y aun así no alcanza el umbral del Gran Premio [7]. La narrativa cómoda de que las máquinas son siempre más baratas que las personas se rompe precisamente en los benchmarks donde se exige razonamiento de nivel humano.
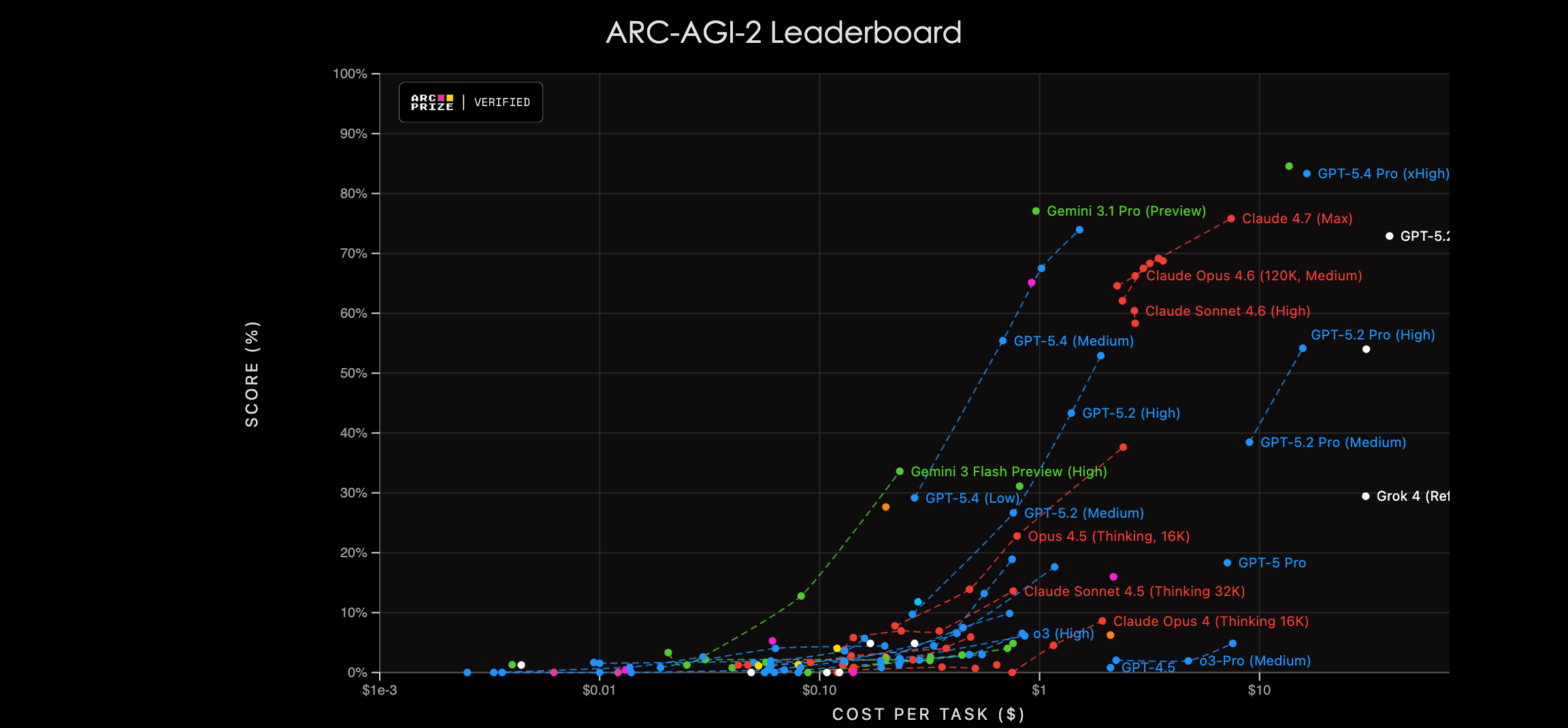
Esta estructura revela algo importante: el razonamiento no es gratuito, ni siquiera para las máquinas. Los modelos que mejores resultados obtienen en benchmarks como HLE o ARC-AGI son precisamente aquellos que usan más cómputo por inferencia. El esfuerzo de inferencia es, hasta hoy, el mejor proxy disponible de capacidad. Y ese esfuerzo tiene un precio que no todos pueden ni deben pagar para cada tarea.
Entre 2025 y 2026, la estructura de precios incorporó otros elementos que vale la pena nombrar: prompt caching con precios diferenciados —reutilizar una instrucción ya procesada cuesta entre cuatro y diez veces menos que procesarla por primera vez—; tarifas explícitas para herramientas y entornos de ejecución como búsqueda web, contenedores de código o agentes; y descuentos opcionales a cambio de compartir datos de entrenamiento [10]. No son detalles menores: son la evidencia de que el mercado está formalizando, tarifario en mano, la distinción entre distintos tipos de cómputo.
Esto importa para el lector no técnico porque implica que cuando un modelo responde mal algo que parece trivial, no siempre es por ignorancia: a veces es porque se usó la versión equivocada para la tarea equivocada. Y cuando responde bien algo difícil, puede ser porque se usaron más recursos de los que el problema justificaba económicamente.
5. IA, IAG e IAS: precisar los términos antes de creer en los titulares
El debate sobre benchmarks no puede separarse del debate sobre hacia dónde va la industria. Por eso conviene precisar tres conceptos que circulan con creciente imprecisión en medios generalistas.
La inteligencia artificial estrecha —ANI, por sus siglas en inglés— es lo que existe hoy: sistemas diseñados para tareas específicas, que pueden ser extraordinariamente buenos en esas tareas pero que no generalizan fuera de ellas de forma autónoma. Los modelos de lenguaje actuales son ANI sofisticados.
La Inteligencia Artificial General —AGI— es el objetivo hipotético de construir un sistema capaz de realizar cualquier tarea cognitiva que un humano pueda realizar, con capacidad de aprender y adaptarse de forma autónoma a dominios nuevos. No existe consenso sobre cuándo ni si se alcanzará. Tampoco existe consenso sobre cómo se mediría. Algunos investigadores, como François Chollet, consideran que los benchmarks actuales son instrumentos insuficientes para declarar su llegada, y que hace falta un salto cualitativo en razonamiento fluido que los modelos actuales no han demostrado [5][7]. Otros creen que la AGI podría surgir de la escalabilidad de los modelos actuales sin un salto cualitativo evidente. El debate es serio y no está resuelto.
La Superinteligencia Artificial —ASI— es un escenario especulativo que plantea sistemas cognitivamente superiores al ser humano en todos los dominios relevantes. Es objeto de debate filosófico y técnico serio, pero también de amplificación mediática que no siempre sirve al lector. Desde Vetus Nova no tomaremos partido en ese debate: lo registramos como territorio de proyección, no de certeza.
Lo que sí es verificable es que la industria persigue estas metas con recursos sin precedentes históricos, y que los benchmarks son uno de los instrumentos con que mide su avance. Entender sus limitaciones es, por tanto, una competencia cívica mínima para quien consume información sobre el sector.
6. La sobreconfianza como falla del sistema
Aquí está la parte que más debería inquietar al usuario cotidiano de estas herramientas.
El paper de HLE dedica un apartado específico al error de calibración, entendido como la discrepancia entre la confianza que el modelo declara en sus respuestas y la precisión real de esas respuestas. La metodología es directa: se pide al modelo que, junto con cada respuesta, reporte una confianza entre 0 y 100%, y se calcula el error de calibración como la diferencia cuadrática media entre confianza declarada y acierto observado. Los autores del paper reportan errores de calibración RMS entre 70% y 89% en todos los modelos pre-release evaluados —GPT-4o, o1, o3-mini, DeepSeek-R1 y otros— y lo resumen en una frase directa: “los modelos con frecuencia entregan respuestas incorrectas con alta confianza en HLE, sin reconocer cuándo las preguntas exceden sus capacidades” [1].
Un análisis posterior de Scale AI, específico sobre los modelos o3 y o4-mini, muestra el fenómeno con más granularidad. En HLE, o3-mini en configuración de alta computación reporta una confianza media del 96% mientras alcanza solo 13,4% de precisión —un error de calibración cercano al 80% [11]. En las curvas de calibración detalladas, las respuestas con confianza declarada superior al 80% aciertan a tasas notoriamente inferiores, a menudo en bandas del 20% al 50% según el modelo. El patrón es consistente entre proveedores y versiones.
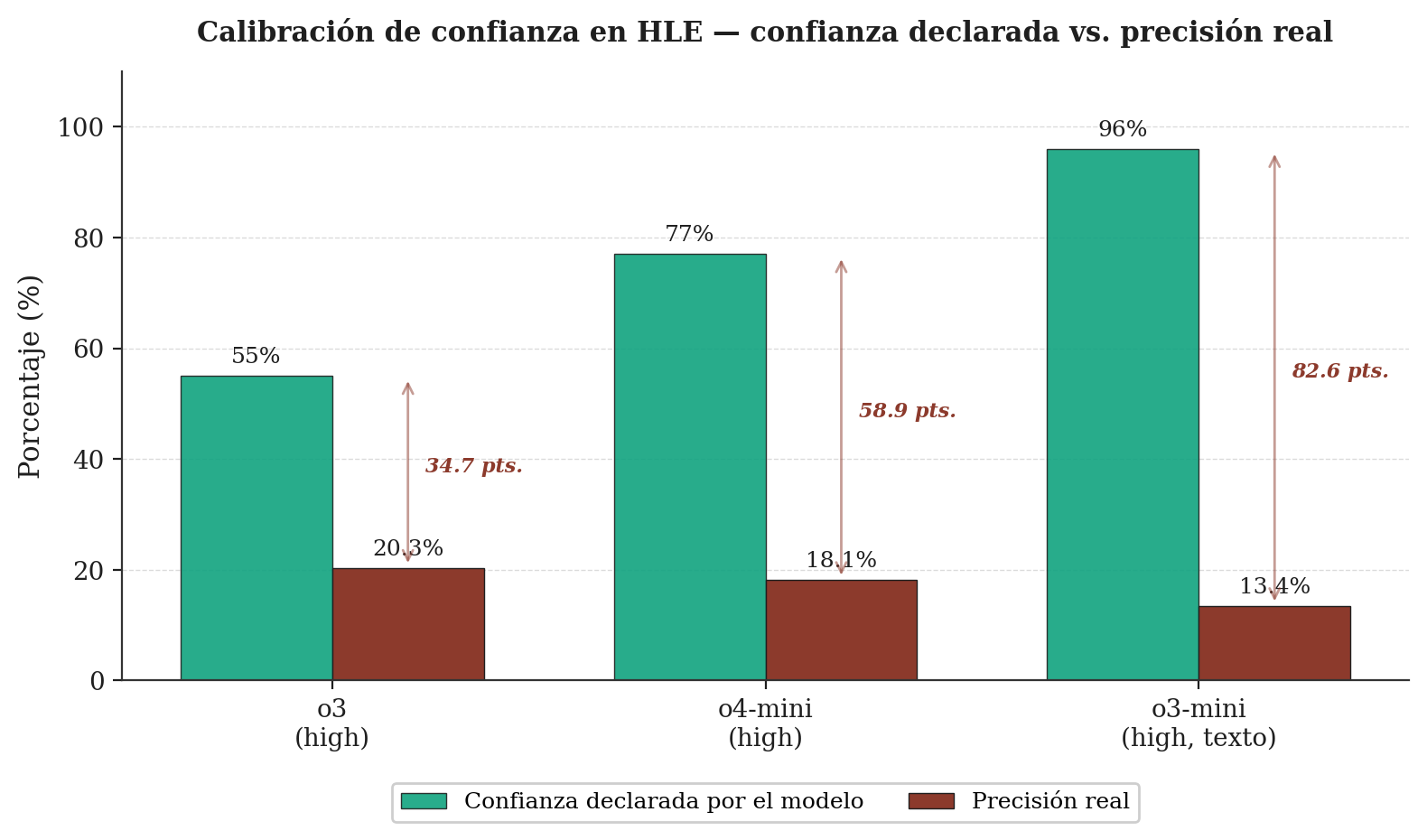
Un sistema bien calibrado dice «no sé» o «no estoy seguro» cuando efectivamente no sabe o no está seguro. Los modelos actuales tienen una tendencia estructural a no hacer eso —en parte porque fueron entrenados para ser útiles y fluidos, no para modelar su propia incertidumbre con precisión.
El peligro no es que la máquina sea ignorante. El peligro es que no lo sepa, y que nosotros tampoco lo notemos.
Esta es la razón más sólida —más sólida que cualquier argumento filosófico sobre la naturaleza de la conciencia— para insistir en el desarrollo del pensamiento crítico como competencia irrenunciable del usuario. No se trata de desconfiar de las herramientas por principio. Se trata de entender que delegar el juicio cognitivo total en un sistema que no calibra bien su propia incertidumbre no es eficiencia: es negligencia.
El pensamiento crítico no es un lujo humanista. Es la interfaz de seguridad que falta en el software.
7. Lo que mide el examen y lo que no mide
Superar un benchmark no es lo mismo que pensar. Y pensar no es lo mismo que investigar. E investigar no es lo mismo que comprender.
Esta cadena de distinciones no es un juego retórico: es la columna vertebral de lo que está genuinamente en disputa cuando la industria anuncia nuevos máximos en pruebas académicas. Los modelos actuales mejoran sus puntajes en benchmarks en parte porque los benchmarks son fijos y los modelos aprenden a moverlos; en parte porque el aumento de cómputo produce mejoras reales y verificables; y en parte porque el diseño de las pruebas, por más cuidadoso que sea, captura solo una fracción de lo que llamamos inteligencia.
Lo que ningún benchmark mide hoy es la capacidad de formular una pregunta que nadie ha formulado antes. Ni la disposición a tolerar la incertidumbre sin resolverla prematuramente. Ni el juicio sobre cuándo un problema está suficientemente bien comprendido como para actuar. Estas son capacidades humanas que no desaparecen por el hecho de que una máquina resuelva bien un examen de postgrado.
La tecnología es el medio. Lo humano es el fin. Y el fin no se delega.
La próxima vez que un titular anuncie que un modelo ha «superado a los humanos» en alguna prueba, vale la pena preguntarse: ¿qué mide exactamente esa prueba? ¿A qué costo computacional se logró ese resultado? ¿Qué tan bien calibrada estaba la confianza del modelo en sus respuestas incorrectas? ¿Se midió bajo restricciones de cómputo comparables a las de un trabajador humano, o con recursos que ningún uso cotidiano podría costear? Las respuestas a esas preguntas no niegan el progreso. Lo sitúan. Y situar el progreso es, precisamente, lo que nos permite aprovecharlo sin perdernos en él.
Referencias
[1] Center for AI Safety, Scale AI & HLE Contributors Consortium. A benchmark of expert-level academic questions to assess AI capabilities (“Humanity’s Last Exam”). arXiv:2501.14249, enero 2025. Publicado en Nature 649, 1139–1146 (28 enero 2026). DOI: 10.1038/s41586-025-09962-4. https://arxiv.org/abs/2501.14249
[2] Sitio oficial del proyecto Humanity’s Last Exam, mantenido en agi.safe.ai. Incluye changelog del bug bounty (febrero–marzo 2025) y anuncio del lanzamiento de HLE-Rolling en octubre de 2025. https://agi.safe.ai
[3] Humanity’s Last Exam Benchmark Leaderboard. Artificial Analysis. Snapshot consultado el 22 de abril de 2026. https://artificialanalysis.ai/evaluations/humanitys-last-exam
[4] AI Model Benchmarks. LMCouncil. Snapshot de 5 de marzo de 2026. https://lmcouncil.ai/benchmarks
[5] On the Measure of Intelligence. Chollet, F. arXiv:1911.01547, noviembre 2019. https://arxiv.org/abs/1911.01547
[6] Announcing ARC-AGI-2 and ARC Prize 2025. ARC Prize Foundation. Post oficial publicado el 24 de marzo de 2025. https://arcprize.org/blog/announcing-arc-agi-2-and-arc-prize-2025
[7] Leaderboard público y página ARC-AGI-2. ARC Prize Foundation. Consultado el 22 de abril de 2026. https://arcprize.org/leaderboard
[8] ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems. arXiv:2505.11831, mayo 2025. https://arxiv.org/abs/2505.11831
[9] ARC-AGI-2 Benchmark Leaderboard. BenchLM.ai. Snapshot de 21 de abril de 2026. https://benchlm.ai/benchmarks/arcAgi2
[10] API Pricing. OpenAI. Página oficial de precios, consultada en abril de 2026. https://developers.openai.com/api/docs/pricing
[11] Calibration of OpenAI o3 and o4-mini on Humanity’s Last Exam. Scale AI. https://scale.com/blog/o3-o4-mini-calibration
[12] Claude Pricing. Anthropic. Consultada en abril de 2026. https://www.anthropic.com/pricing
[13] Gemini Developer API — Pricing (Gemini 3.1 Pro Preview). Google AI for Developers. Consultada en abril de 2026. https://ai.google.dev/gemini-api/docs/pricing
Nota editorial: La Figura 2 es el leaderboard público publicado por ARC Prize Foundation en arcprize.org (dominio público con fines de difusión). Las Figuras 1 y 3 son de elaboración propia a partir de los datos citados en las referencias [1], [3] y [11]. Las citas con número en corchetes remiten a la lista de referencias al final.



