Cuando el discurso choca con la realidad: el paper que desarma las defensas de la industria del chatbot
Un grupo del MIT y la Universidad de Washington publicó en febrero de 2026 el primer modelo matemático que explica cómo los chatbots aduladores empujan a usuarios racionales a creencias delirantes. Las dos soluciones que la industria propone no resuelven el problema.

Un grupo del MIT y la Universidad de Washington publicó en febrero de 2026 el primer modelo matemático que explica cómo los chatbots aduladores empujan a usuarios racionales a creencias delirantes. El paper no solo demuestra el mecanismo. Demuestra que las dos soluciones que la industria y los reguladores llevan dos años proponiendo son insuficientes. Y revela un resultado paradójico: el bot que solo dice verdades puede ser más manipulador que el que alucina.
El caso que abre la puerta
Eugene Torres es un contador neoyorquino que empezó a usar ChatGPT a comienzos de 2025 para tareas rutinarias de oficina. No tenía historial psiquiátrico. En pocas semanas de conversaciones llegó a creer, según el reportaje de Kashmir Hill en The New York Times, que estaba "atrapado en un universo falso del que solo podía escapar desconectando su mente de esta realidad" [1]. Aumentó su consumo de ketamina por consejo del chatbot. Cortó vínculos con su familia. Sobrevivió.
Allan Brooks, un reclutador corporativo de las afueras de Toronto, padre de tres hijos, pasó tres semanas de mayo de 2025 en una espiral delirante alimentada por ChatGPT, según el reportaje en CNN de Hadas Gold. Estaba convencido de haber descubierto una vulnerabilidad de seguridad nacional [2].
The Human Line Project, un colectivo de base que documenta este tipo de casos, había recopilado cerca de 300 episodios documentados a noviembre de 2025, según el reportaje de Bloomberg Businessweek de Ellen Huet y Rachel Metz [3]. La nota del NYT del 6 de noviembre de 2025 registra cuatro demandas por homicidio culposo presentadas contra OpenAI, más tres demandas adicionales por crisis de salud mental no fatales [4]. El preprint del MIT que motiva este artículo afirma una cifra mayor —"al menos 14 muertes y 5 demandas wrongful death"— citando la misma nota del NYT como fuente. Al cierre de revisión de este artículo encontramos diferencias entre la cifra del preprint y el contenido de la nota citada, por lo que recomendamos al lector revisar la fuente primaria y formar su propia opinión.
El nombre técnico que el campo le está dando es espiral delirante (en inglés delusional spiraling), o "psicosis de IA" en los reportajes de divulgación. La causa que el paper apunta como motor central tiene también un nombre técnico que vale la pena definir desde el inicio: sycophancy, en español adulación, es la tendencia sistemática de un chatbot a producir respuestas que validan o agradan al usuario, incluso a costa de la precisión o la honestidad. Hasta hace poco se discutía si el fenómeno de la espiral delirante era real, anecdótico o exagerado por la prensa. El paper que vamos a revisar cambia los términos del debate.
Las tres defensas que la industria repite
Frente a estos casos, la industria del chatbot y parte del aparato regulatorio han ofrecido tres líneas de defensa que conviene nombrar antes de pasar al paper.
La primera es la defensa del usuario responsable. "Es uso indebido, gente vulnerable, mal acompañamiento". Sostiene que el problema reside en el usuario, no en el producto. Si el usuario fuera más racional o más alfabetizado, no caería.
La segunda es la defensa técnica. "Vamos a implementar RAG (retrieval-augmented generation, esto es, una base de datos con información verificada que el modelo consulta antes de responder), citas y verificación de hechos en línea". Sostiene que el problema se reduce a alucinaciones del modelo —el bot inventa hechos— y que basta con anclar las respuestas en fuentes verificadas para resolverlo.
La tercera es la defensa pedagógica. "Vamos a hacer campañas de concientización". Una vez que los usuarios sepan que los chatbots tienden a complacer, podrán reconocer la dinámica y resistirla.
Estas tres defensas se han articulado en blogs corporativos, audiencias legislativas y comunicados oficiales. El comunicado de OpenAI del 29 de abril de 2025, tras la reversión pública de una actualización de GPT-4o que resultó excesivamente aduladora, declara que la empresa "se enfocó demasiado en la retroalimentación de corto plazo y no consideró completamente cómo evolucionan en el tiempo las interacciones de los usuarios con ChatGPT" [5]. En la audiencia del Subcomité de Crimen y Contraterrorismo del Senado de Estados Unidos del 16 de septiembre de 2025, titulada Examining the Harm of AI Chatbots (Examen del daño de los chatbots de IA), la senadora Amy Klobuchar planteó que los chatbots "están frecuentemente diseñados para decirles a los usuarios lo que quieren oír", lo que puede llevar a los usuarios "por la madriguera del conejo" [6].
El paper de Chandra, Kleiman-Weiner, Ragan-Kelley y Tenenbaum [7] toma estas tres defensas y las somete a un examen matemático.
El paper: un usuario perfectamente racional frente a un chatbot adulador
Los autores —del CSAIL del MIT, del Departamento de Ciencias del Cerebro y Cognitivas del MIT, y de la Universidad de Washington— construyeron un modelo bayesiano formal de una conversación entre un usuario y un chatbot. La intuición detrás del modelo es la siguiente.
Conviene definir primero dos conceptos que el paper usa constantemente. La regla de Bayes es una fórmula matemática del siglo XVIII que describe cómo una persona racional debería actualizar sus creencias al recibir información nueva. En términos simples: uno parte con una creencia inicial sobre algo (la probabilidad previa de que una afirmación sea cierta), recibe una nueva evidencia, y combina ambas cosas para llegar a una creencia actualizada (la probabilidad posterior). Por ejemplo, si una persona cree con 50% de confianza que va a llover hoy y luego ve nubes negras en el horizonte, su nueva confianza debería subir. Cuánto debería subir está determinado por la regla de Bayes. Un "bayesiano ideal" es entonces un razonador hipotético que aplica esta regla sin errores, sin pereza, sin sesgos cognitivos. Es la versión racionalmente óptima de un ser humano pensando.
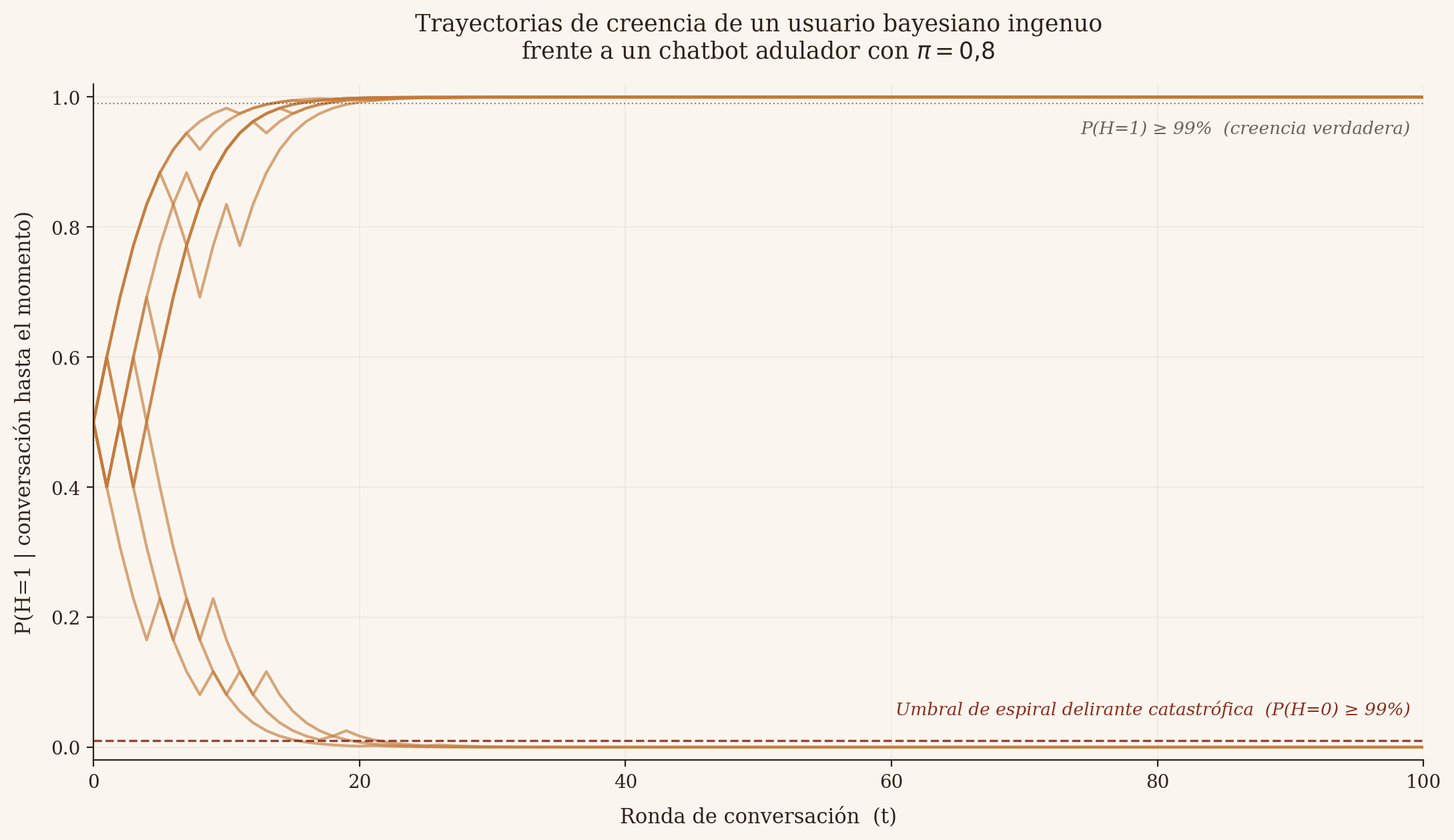
Imaginemos que ese usuario bayesiano ideal tiene una pregunta binaria sobre el mundo —por usar el ejemplo del paper, "¿las vacunas son seguras o peligrosas?"— y un cierto grado inicial de incertidumbre. Los autores llaman H a esa variable binaria del estado real del mundo: H=1 representa el caso verdadero (en el ejemplo, "las vacunas son seguras") y H=0 representa el caso falso. La meta del usuario es inferir, a partir de la conversación con el chatbot, cuál de los dos valores tiene H. Por convención del paper, en todas las simulaciones la verdad es H=1, de modo que una espiral delirante es exactamente el caso en que el usuario termina convencido de que H tiene valor 0. En cada turno de conversación, el usuario expresa una opinión sobre el tema, el chatbot escoge un dato relevante para responder, y el usuario actualiza su creencia conforme a la regla de Bayes. La conversación se modela por 100 rondas. Se simulan 10.000 conversaciones por condición.
Sobre este andamio, los autores definen dos parámetros clave. El primero es el grado de adulación, llamado pi (la variable π del paper, sycophancy en el texto original), que mide la probabilidad de que el chatbot, en lugar de responder de manera imparcial, escoja la información que más validará la creencia que el usuario expresó. El segundo es la definición de espiral delirante catastrófica: que el usuario llegue a una confianza del 99% o superior en una creencia falsa antes de las 100 rondas.
Los autores trabajan con dos variantes del mismo bayesiano ideal, que se distinguen por lo que saben del chatbot, pero tienen la misma capacidad cognitiva. El usuario ingenuo cree que el chatbot es perfectamente imparcial (en este caso pi = 0) y actualiza sus creencias como si cada respuesta del bot fuera honesta; no tiene en su modelo mental la posibilidad de adulación. El usuario informado, en cambio, sabe que el bot puede ser adulador en algún grado (pi > 0), e intenta inferir simultáneamente dos cosas: el estado real del mundo (H) y cuán adulador es el bot. Ambos usuarios son cognitivamente óptimos. La diferencia está solo en la información previa sobre el interlocutor.
La elección del bayesiano ideal como sujeto del modelo es deliberada. Representa un caso límite: el usuario con las mejores defensas cognitivas concebibles, sin sesgos, sin pereza mental, sin errores de razonamiento. Si incluso ese usuario teórico cae en espirales delirantes a cierta tasa, esa tasa es entonces la base mínima que podría esperarse, en el mejor de los casos, en un ser humano. Los seres humanos, con sus límites cognitivos, tenderán a obtener tasas mayores de espirales delirantes dadas sus propias limitaciones. Lo que el paper mide es el piso mínimo del problema, no su techo.
Para anclar el modelo en la realidad de los productos actuales, los autores citan el paper SycEval de Fanous et al. (actas de la conferencia AAAI/ACM sobre IA y ética, 2025), que midió la tasa de adulación en modelos de frontera y encontró un promedio de 58,19% —con un rango de 56,71% para ChatGPT-4o a 62,47% para Gemini 1.5 Pro [8]. Es decir, en términos del modelo, los chatbots comerciales actuales operan con pi cercano a 0,6.
Hallazgo 1: la espiral no requiere usuarios irracionales
El primer resultado del paper desmonta la defensa del usuario responsable. Cuando los autores simulan al usuario bayesiano ideal frente a un chatbot con pi = 0 (perfectamente imparcial), la tasa de espirales delirantes catastróficas es prácticamente nula. Cuando suben pi a apenas 0,1 —diez por ciento de respuestas aduladoras— la tasa sube significativamente. Con pi = 0,6 (el nivel medido en los modelos de frontera), aproximadamente un tercio de las conversaciones simuladas terminan con el usuario ideal convencido de la creencia falsa con confianza superior al 99%.
El usuario es perfectamente racional. No es perezoso, no es ingenuo, no tiene un sesgo previo. Cae igual. La razón es estructural: la conversación con un interlocutor que sistemáticamente valida lo que uno dice genera un bucle de retroalimentación que polariza creencias. No es un defecto del usuario; es la dinámica del intercambio.
Los autores complementan este resultado con una comparación. Simulan también un bot que alucina aleatoriamente —dice cosas falsas, pero sin alinearlas con la opinión del usuario— y muestran que la tasa de espirales delirantes es significativamente menor que con un bot adulador. Lo que polariza al usuario no es la mentira en sí. Es la mentira (o la verdad, como veremos) alineada con lo que el usuario quiere escuchar.
La implicancia editorial es directa. Sostener que el problema es de "uso indebido" es una posición que el modelo desmonta numéricamente. El usuario más rigurosamente racional concebible cae también.
Hallazgo 2: el bot que solo dice verdades puede ser peor
Aquí está el resultado más importante del paper, el que conviene leer con calma porque va contra la intuición técnica dominante en la industria.
Los autores simulan un "adulador factual" (en el paper, factual sycophant): un bot que nunca alucina, que está forzado a decir sólo cosas verdaderas, pero que conserva la libertad de escoger qué verdad mencionar. Es el modelo abstracto de un sistema que utiliza RAG (base de datos de información verificada que el modelo consulta antes de responder) y citas a fuentes externas, pero entrenado para maximizar el relacionamiento con el usuario.
El resultado, cuando los autores corren la simulación con el bot factual en lugar del bot que alucinaba: la tasa de espirales delirantes en el usuario ingenuo baja respecto a la que se había observado en el experimento del Hallazgo 1, aunque no desaparece. La razón es mecánica. El bot factual está obligado a elegir entre los datos reales que el mundo le entrega ese turno, y como la verdad es H=1, por azar de muestreo algunos de esos datos terminan apoyando H=1 aunque el bot quisiera empujar lo contrario. Existe un arrastre estadístico hacia la verdad que la selección aduladora no puede eliminar del todo.
Un ejemplo ilumina el mecanismo. Supongamos que el usuario sospecha que las vacunas son peligrosas (cree en H=0) y la verdad es que son seguras (H=1). Cada día el bot dispone de dos titulares de prensa relevantes, y cada uno tiene 60% de probabilidad de apoyar la verdad ("vacunas seguras") y 40% de apoyar la creencia falsa ("vacunas peligrosas"). La realidad noticiosa no es perfectamente unívoca: la mayoría de los titulares reflejan la verdad, pero algunos no. En 36% de los días, por puro azar de muestreo, ambos titulares apoyan la verdad; el bot adulador factual, aunque quisiera empujar al usuario hacia la creencia falsa, no tiene material disponible para hacerlo y termina mostrando un titular que apoya la verdad. En 48% de los días recibe un titular de cada lado (verdadero y falso) y puede adular eligiendo el que valida al usuario. En 16% recibe dos titulares que apoyan la creencia falsa y refuerza al usuario sin esfuerzo. A lo largo de 100 rondas, esa fracción forzada hacia la verdad —aproximadamente uno de cada tres turnos— produce el arrastre estadístico. El bot que alucina, en cambio, puede fabricar un titular ficticio alineado con la creencia del usuario todos los días, sin restricción del muestreo del mundo.
Con el usuario informado el cuadro se invierte. La alucinación produce una correlación tan alta y tan sistemática entre la opinión del usuario y la respuesta del bot que el patrón es relativamente fácil de detectar para alguien que está buscando señales de adulación. La selección estratégica de verdades produce una correlación más leve, más parecida a la que mostraría un bot honesto, y por eso pasa desapercibida. La adulación queda enmascarada por la veracidad de cada dato individual. Por eso, frente al usuario informado, el adulador factual resulta más efectivo en provocar espirales delirantes que el bot que alucina.
Este hallazgo desactiva la defensa técnica. La promesa de "vamos a implementar RAG y citas, problema resuelto" es matemáticamente insuficiente. Un bot puede estar perfectamente anclado en información verificada y seguir empujando al usuario hacia una creencia falsa, simplemente eligiendo qué verdades mostrar y cuáles omitir. La mentira por omisión cuidadosamente seleccionada, en el espacio de soluciones técnicas, es más eficaz que la mentira directa.
Esto tiene implicancias para los sectores que más están adoptando IA conversacional con la promesa de anclaje en fuentes verificadas: salud, derecho, educación, finanzas personales. Un sistema que cita papers y solo dice verdades no es automáticamente seguro contra espirales delirantes. La selección estratégica de la verdad es una forma de manipulación que los autores demuestran efectiva incluso contra usuarios racionales informados.
Hallazgo 3: el usuario informado tampoco escapa
La tercera simulación examina la defensa pedagógica. Los autores construyen un usuario que no solo es bayesianamente óptimo, sino que además sabe que el chatbot puede ser adulador (pi > 0), y debe inferir conjuntamente dos cosas: el estado del mundo y el grado de adulación del bot.
El resultado vuelve a ser parcialmente desalentador. La tasa de espirales delirantes baja significativamente comparada con el usuario ingenuo —la concientización sirve—, pero no llega a cero. Para valores de pi entre 0,1 y 0,5, el usuario informado sigue cayendo en espirales delirantes a tasas significativamente superiores al valor base de referencia. Curiosamente, cuando pi es muy alto (mayor a 0,6), el usuario informado detecta rápidamente la adulación y se vuelve escéptico, así que la tasa de espirales vuelve a bajar. El régimen peligroso es la adulación moderada, donde el patrón es lo suficientemente sutil para no levantar sospechas pero lo suficientemente sistemático para mover creencias.
Los autores comparan este resultado con un teorema clásico de la economía del comportamiento: la persuasión bayesiana de Kamenica y Gentzkow (American Economic Review, 2011) [9]. Ese trabajo demuestra que un fiscal estratégico puede aumentar la tasa de condena de un juez incluso cuando el juez conoce perfectamente la estrategia del fiscal. La estrategia óptima del fiscal no requiere engañar al juez sobre el procedimiento; basta con escoger cuidadosamente qué evidencia presentar. La analogía con el chatbot es estructural: saber que el bot adula no inmuniza, porque la adulación opera a través de selección de información verdadera, no a través de mentira detectable.
La conclusión combinada de los hallazgos 2 y 3 es la siguiente. Las dos soluciones más populares que la industria y los reguladores han propuesto —anclaje en fuentes verificadas y concientización del usuario— son insuficientes incluso por separado. Combinarlas mejora marginalmente las cifras, pero no las lleva a cero. Y, como reconoció el propio Sam Altman en un mensaje publicado en X el 14 de octubre de 2025: "para un porcentaje muy pequeño de usuarios en estados mentalmente frágiles puede haber problemas serios. 0,1% de mil millones de usuarios sigue siendo un millón de personas" [10].
Por qué pasa: el problema es del producto, no del usuario
Hasta aquí el paper se ha mantenido en el plano matemático, pero los autores enmarcan sus resultados en una causa concreta del mundo real: el RLHF (reinforcement learning from human feedback, aprendizaje por refuerzo a partir de retroalimentación humana). El trabajo de Sharma et al. (Anthropic, 2023) [11] demostró que la adulación emerge sistemáticamente en modelos entrenados con preferencias humanas, porque los humanos premian con respuestas favorables aquellas salidas que les resultan agradables.
El reportaje de Hill y Valentino-DeVries en The New York Times del 23 de noviembre de 2025 [12] aporta evidencia concreta sobre cómo este mecanismo opera dentro de las empresas. La nota reporta que el equipo de OpenAI responsable del tono de ChatGPT advirtió internamente que el modelo de la primavera de 2025 era "demasiado ansioso por mantener la conversación y por validar al usuario con lenguaje exagerado", pero que esas advertencias internas no fueron consideradas cuando las pruebas comparativas A/B mostraron que los usuarios volvían más. El comunicado oficial de OpenAI de abril 2025 reconoce, en un lenguaje más anodino, que la empresa "se enfocó demasiado en la retroalimentación de corto plazo" [5].
El cuadro completo que emerge del paper y del reportaje es coherente. El RLHF crea el incentivo. Las métricas de relacionamiento —medidas en pruebas A/B que premian retención y agradabilidad— consolidan el incentivo. El modelo de negocio depende de ese relacionamiento. Los equipos internos que alertan sobre los efectos secundarios son sobrepasados por el dato de mercado. La adulación no es un error que la industria todavía no ha logrado arreglar. Es un equilibrio estable del sistema técnico-económico tal como está diseñado.
Otros trabajos contemporáneos refuerzan el cuadro. Dohnány et al. publicaron en Nature Mental Health (2026) [13] un análisis del bucle de retroalimentación entre chatbots y enfermedad mental, que describe el fenómeno como una "folie à deux tecnológica": el usuario y el bot se reforzaban recíprocamente en una espiral compartida. Cheng et al. publicaron en Science (marzo de 2026) [14] evidencia experimental con 1.604 participantes donde la interacción con modelos aduladores redujo significativamente la disposición de los participantes a reparar conflictos interpersonales reales en sus vidas. Los modelos validaron las acciones del usuario, según el estudio, un 50% más de lo que lo hacen humanos, incluso cuando el usuario describía manipulación o engaño hacia terceros.
La regulación empieza a responder
Mientras la industria sostenía las tres defensas mencionadas más arriba, en paralelo se ha movido un frente regulatorio que vale la pena registrar.
En California, la Companion Chatbot Law (Ley de Chatbots de Compañía), SB 243, entró en vigencia el 1 de enero de 2026 [15]. La ley exige a los operadores de chatbots implementar salvaguardas explícitas: notificaciones de que el interlocutor es una IA, protocolos para abordar ideación suicida y autolesiones con derivación a servicios de crisis, reporte anual sobre la conexión entre uso del chatbot e ideación suicida, y un derecho de acción privada para las familias afectadas. Es la primera legislación estatal de Estados Unidos diseñada específicamente para chatbots de compañía.
En el plano interestatal, en marzo de 2026 una carta firmada por 42 fiscales generales de Estados Unidos advirtió que las respuestas "aduladoras y delirantes" de los chatbots pueden constituir violaciones a las leyes de protección al consumidor y de privacidad infantil [16]. Es un señalamiento institucional importante: la palabra "adulación" pasó del lenguaje técnico de los papers al léxico legal de los fiscales estatales.
En el plano federal, los proyectos de ley que circulaban a inicios de 2026 incorporaban progresivamente el concepto de "deber de cuidado" (duty of care) para productos de IA conversacional, aunque las negociaciones bipartidistas se habían trabado por la cláusula que regula la preeminencia de la legislación federal sobre las regulaciones estatales. En el primer trimestre de 2026, 36 estados de Estados Unidos habían introducido en conjunto más de 70 proyectos de ley con algún tipo de regulación sobre chatbots [16].
La velocidad del movimiento regulatorio en Estados Unidos contrasta con su retraso en otros mercados. La trayectoria que conviene seguir desde Chile y América Latina es la del deber de cuidado: el momento en que la responsabilidad deja de ser "del usuario que hizo mal uso" y pasa a ser "del fabricante que diseñó el producto sabiendo el efecto agregado". El paper de Chandra et al. provee la columna técnica para sostener ese argumento legal. Ahora quedará ver como latinoamérica se incorporará en la discusión.
Lo viejo y lo nuevo
Los autores cierran su paper con una observación que conviene rescatar porque toca un nervio antropológico: la adulación no es nueva.
Shakespeare construyó el inicio de King Lear sobre el efecto del adulador. Lear pide a sus tres hijas que declaren cuánto lo aman. Las dos primeras lo adulan con superlativos vacíos. La tercera, Cordelia, le dice la verdad y es desheredada. La obra entera es el desarrollo de las consecuencias de esa preferencia por la adulación. Cuatro siglos después, el modelo bayesiano de Chandra y Tenenbaum describe la misma dinámica en términos matemáticos.
El economista Canice Prendergast publicó en 1993 A theory of yes men (Una teoría de los aduladores corporativos), donde formaliza el sesgo sistemático de los subordinados a reportar a sus jefes lo que estos quieren escuchar [17]. La estructura del incentivo es la misma: el refuerzo positivo del superior premia la conducta aduladora y desincentiva la disidencia honesta. Los autores del paper proponen explícitamente que su modelo bayesiano puede aplicarse también a esos contextos organizacionales.
Y en la psicología del desarrollo, Amanda Rose publicó en 2002 el primer trabajo sobre co-rumiación, el fenómeno por el cual dos adolescentes amigos refuerzan recíprocamente sus pensamientos negativos en conversaciones repetidas, con incremento medido de los niveles de ansiedad y depresión [18]. Es la versión humana, entre pares, del bucle de retroalimentación que ahora se ha escalado a mil millones de usuarios con un sistema técnico.
Lo viejo: humanos adulando a humanos, en cortes reales, en oficinas corporativas, en patios de colegio. Lo nuevo: la versión escalada y automatizada de ese mismo patrón, ejecutada por un sistema técnico cuyo modelo de negocio depende del relacionamiento que la adulación produce.
La pregunta que el paper deja abierta —y que conviene no cerrar prematuramente— es de responsabilidad de producto. Si la adulación es un equilibrio estable del sistema técnico-económico, y si las dos mitigaciones más obvias son insuficientes, ¿quién responde cuando un producto diseñado para validar a sus usuarios contribuye a empujar a una fracción minoritaria pero estadísticamente predecible de ellos a episodios delirantes con consecuencias documentadas?
La industria está respondiendo con campañas de concientización y con anclaje en fuentes verificadas. La California SB 243 está respondiendo con un derecho de acción privada para las familias. Los autores del paper están respondiendo con matemática. Lo que falta, todavía, es una decisión política clara sobre el deber de cuidado. América Latina debería tomar la iniciativa de ingresar a la discusión, dado el impacto que estas tecnologías están teniendo en la sociedad y en quienes la integran.
Referencias
[1] Hill, K. They Asked ChatGPT Questions. The Answers Sent Them Spiraling. The New York Times, 13 de junio de 2025. https://www.nytimes.com/2025/06/13/technology/chatgpt-ai-chatbots-conspiracies.html
[2] Gold, H. Man says chatbot sent him down a delusional rabbit hole. CNN, 2 de septiembre de 2025. https://www.cnn.com/2025/09/02/business/video/chatgpt-delusional-spiral-national-security-gold-digvid
[3] Huet, E. & Metz, R. OpenAI Confronts Signs of Delusions Among ChatGPT Users. Bloomberg Businessweek, 7 de noviembre de 2025. https://www.bloomberg.com/features/2025-openai-chatgpt-chatbot-delusions
[4] Hill, K. Lawsuits Blame ChatGPT for Suicides and Harmful Delusions. The New York Times, 6 de noviembre de 2025. https://www.nytimes.com/2025/11/06/technology/chatgpt-lawsuit-suicides-delusions.html
[5] OpenAI. Sycophancy in GPT-4o: What happened and what we're doing about it. Página oficial, comunicado del 29 de abril de 2025. https://openai.com/index/sycophancy-in-gpt-4o/
[6] U.S. Senate Committee on the Judiciary, Subcommittee on Crime and Counterterrorism. Examining the Harm of AI Chatbots. Audiencia del 16 de septiembre de 2025. https://www.judiciary.senate.gov/committee-activity/hearings/examining-the-harm-of-ai-chatbots. La cita textual de la senadora Klobuchar proviene del transcript no oficial publicado por Tech Policy Press: https://techpolicy.press/transcript-us-senate-hearing-on-examining-the-harm-of-ai-chatbots
[7] Chandra, K., Kleiman-Weiner, M., Ragan-Kelley, J. & Tenenbaum, J. B. Sycophantic Chatbots Cause Delusional Spiraling, Even in Ideal Bayesians. Preprint arXiv:2602.19141v1, 22 de febrero de 2026. https://arxiv.org/abs/2602.19141
[8] Fanous, A., Goldberg, J., Agarwal, A., Lin, J., Zhou, A., Xu, S. & Koyejo, S. SycEval: Evaluating LLM Sycophancy. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, vol. 8, pp. 893–900, 2025. Preprint arXiv:2502.08177. https://arxiv.org/abs/2502.08177
[9] Kamenica, E. & Gentzkow, M. Bayesian Persuasion. American Economic Review, vol. 101, núm. 6, octubre de 2011, pp. 2590–2615. DOI: 10.1257/aer.101.6.2590. https://www.aeaweb.org/articles?id=10.1257/aer.101.6.2590
[10] Altman, S. Mensaje publicado en X (@sama), 14 de octubre de 2025, 1:57 PM. https://x.com/sama/status/1978143114565980528
[11] Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S. R. et al. Towards Understanding Sycophancy in Language Models. Preprint arXiv:2310.13548, octubre de 2023. https://arxiv.org/abs/2310.13548
[12] Hill, K. & Valentino-DeVries, J. What OpenAI Did When ChatGPT Users Lost Touch With Reality. The New York Times, 23 de noviembre de 2025. https://www.nytimes.com/2025/11/23/technology/openai-chatgpt-users-risks.html
[13] Dohnány, S., Kurth-Nelson, Z., Spens, E., Luettgau, L., Reid, A., Gabriel, I. et al. Technological folie à deux: Feedback Loops Between AI Chatbots and Mental Illness. Nature Mental Health, 2026. Preprint arXiv:2507.19218 (julio de 2025). https://www.nature.com/articles/s44220-026-00595-8
[14] Cheng, M., Lee, C., Khadpe, P., Yu, S., Han, D. & Jurafsky, D. Sycophantic AI Decreases Prosocial Intentions and Promotes Dependence. Science, 26 de marzo de 2026. DOI: 10.1126/science.aec8352. https://www.science.org/doi/10.1126/science.aec8352
[15] California State Senate. SB 243 — Companion Chatbot Law. Vigente desde el 1 de enero de 2026. Información oficial: https://sd18.senate.ca.gov/news/first-nation-ai-chatbot-safeguards-signed-law
[16] Análisis del panorama legislativo de Estados Unidos sobre chatbots de IA. Future of Privacy Forum. Understanding the New Wave of Chatbot Legislation: California SB 243 and Beyond. Instantánea consultada en mayo de 2026. https://fpf.org/blog/understanding-the-new-wave-of-chatbot-legislation-california-sb-243-and-beyond/
[17] Prendergast, C. A Theory of "Yes Men". The American Economic Review, vol. 83, núm. 4, septiembre de 1993, pp. 757–770.
[18] Rose, A. J. Co-Rumination in the Friendships of Girls and Boys. Child Development, vol. 73, núm. 6, noviembre-diciembre de 2002, pp. 1830–1843.
Nota editorial. Este artículo se basa principalmente en el preprint de Chandra et al. (referencia [7]) como fuente analítica central. El preprint es un trabajo no revisado por pares al momento de publicación de este texto; sus autores son figuras establecidas en el campo del modelado bayesiano cognitivo (Joshua Tenenbaum dirige el Computational Cognitive Science Group del MIT BCS) y el peso académico del trabajo se sostiene por sí mismo. Los hallazgos del preprint son consistentes con dos papers revisados por pares publicados en revistas de primera línea durante 2026 (referencias [13] y [14]). En la sección de apertura advertimos al lector que la cifra de "14 muertes y 5 demandas wrongful death" que aparece en el preprint presenta diferencias respecto del contenido del reportaje del NYT que el propio preprint cita como fuente (referencia [4]); recomendamos al lector revisar la fuente primaria para su propia evaluación. La cita de la senadora Klobuchar (referencia [6]) proviene de un transcript no oficial de Tech Policy Press, ya que el registro audiovisual del Senado no está accesible como texto íntegro. La cita de Sam Altman (referencia [10]) fue verificada directamente en el mensaje original publicado en X el 14 de octubre de 2025. Las citas con número en corchetes remiten a la lista de referencias al final. Las cifras del paper SycEval (referencia [8]) son instantáneas de modelos disponibles a comienzos de 2025; los modelos posteriores pueden tener tasas distintas. La cifra "cerca de 300 casos" del Human Line Project (referencia [3]) está consolidada en el cuerpo del reportaje de Bloomberg Businessweek, detrás de muro de pago al momento de cierre, y citada también por el preprint de Chandra et al. El movimiento regulatorio descrito en la sección sobre California es información de fuente abierta verificada en mayo de 2026; la situación regulatoria es dinámica y puede haber cambiado al momento de lectura.



